Clinical research generates a large amount of data: protocol-defined assessments, CRF data, laboratory results, adverse events, exposure records, endpoint data, statistical analysis datasets, tables, listings, figures, metadata, and regulatory submission packages.
Without standards, every sponsor, CRO, vendor, and system may describe the same clinical concept differently.
That is exactly the problem CDISC standards were created to solve.
The Clinical Data Interchange Standards Consortium (CDISC) provides globally used standards for structuring, exchanging, analyzing, and submitting clinical and nonclinical research data. CDISC Foundational Standards support the research process from protocol and data collection through tabulation, analysis, exchange, reporting, and submission. (CDISC – Foundational)
For clinical data teams, CDISC is not just a regulatory requirement. It is a shared language between clinical operations, data management, biostatistics, statistical programming, medical writing, quality assurance, technology vendors, and regulatory reviewers.
In practice, CDISC helps answer a simple but critical question:
Can we understand, trace, reproduce, and review the data consistently across the full clinical trial lifecycle?
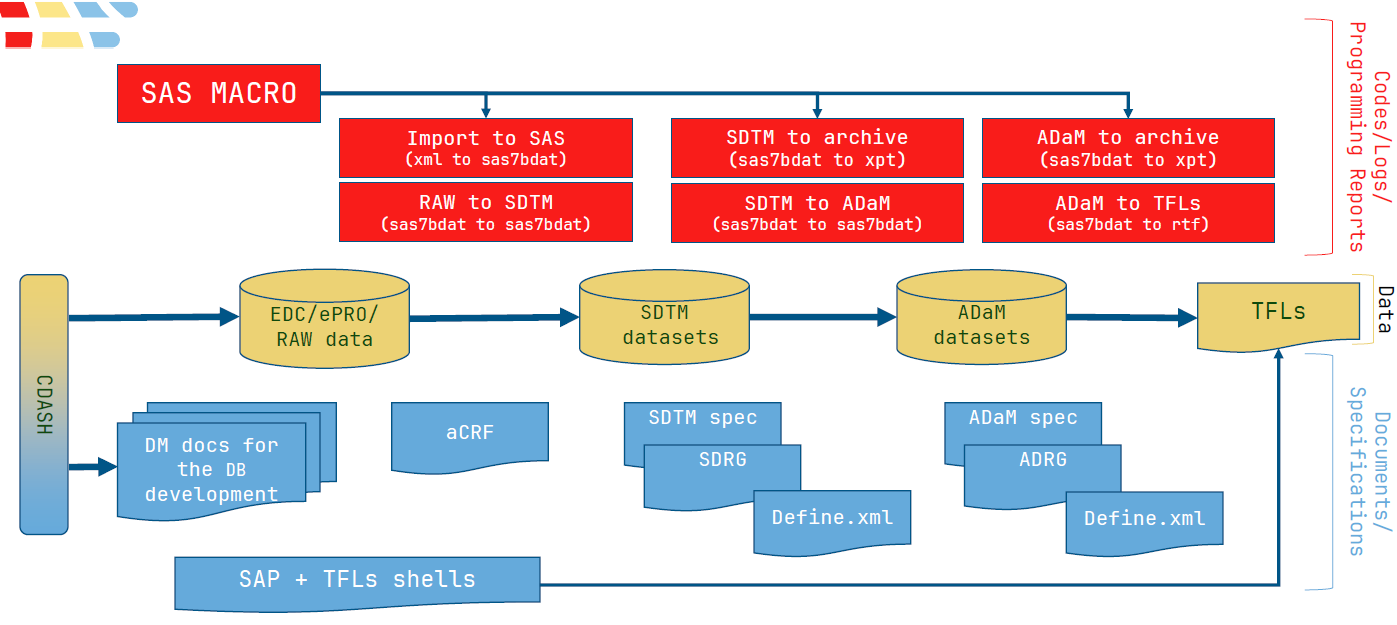
TUNECT’s data collection/analysis lifecycle explanation
The CDISC Standards Lifecycle
A useful way to understand CDISC is to think of it as a lifecycle.
Planning → Data Collection → Data Tabulation → Data Analysis → Data Exchange / Submission
This is why the common CDISC model is often shown as:
Protocol / Study Design → CDASH → SDTM → ADaM with exchange standards such as ODM, Define-XML, Dataset-JSON, Dataset-XML, Analysis Results Standard, and LAB supporting movement of data and metadata between systems.
CDISC Content Standards
CDISC content standards define how clinical and nonclinical data should be structured and interpreted. These standards help ensure that data collected in different studies, countries, vendors, and systems can be understood in a consistent way.
1. Protocol, Study Design, and DDF / USDM
Historically, CDISC included the Protocol Representation Model (PRM) to support structured protocol representation. Today, the more current direction is strongly connected with Digital Data Flow (DDF) and the Unified Study Definitions Model (USDM).
USDM supports the representation of structured study definitions, including elements such as objectives, endpoints, eligibility criteria, activities, schedules, and study design information. CDISC describes USDM as part of the Digital Data Flow initiative, developed with TransCelerate, to support digital protocol workflows and interoperability across clinical systems. (CDISC – DDF)
This is important because protocol design is where many downstream data decisions begin. If objectives, endpoints, estimands, assessments, visits, and timepoints are structured early, it becomes easier to build CRFs, map data into SDTM, define ADaM datasets, and generate traceable outputs.
A related point is that CDISC’s protocol terminology was retired in March 2026 and superseded by ICH M11 protocol terminology, reinforcing the broader shift toward structured, interoperable study-definition standards rather than protocol text alone. (CDISC – CT)
In practical terms: Better-structured study definitions lead to better-structured downstream data.
2. CDASH: Clinical Data Acquisition Standards Harmonization
CDASH defines how data should be collected at the source. It supports standard CRF design and helps align collected data with downstream SDTM requirements.
CDISC describes CDASH as a standard way to collect data consistently across studies and sponsors so that collection formats provide clear traceability into SDTM.
For example, instead of every study collecting adverse event onset date, severity, relationship, and outcome in slightly different ways, CDASH provides a harmonized approach that makes later SDTM mapping more predictable.
From a practical programming perspective, good CDASH implementation reduces ambiguity, improves CRF-to-SDTM traceability, and can prevent many downstream data cleaning and mapping issues.
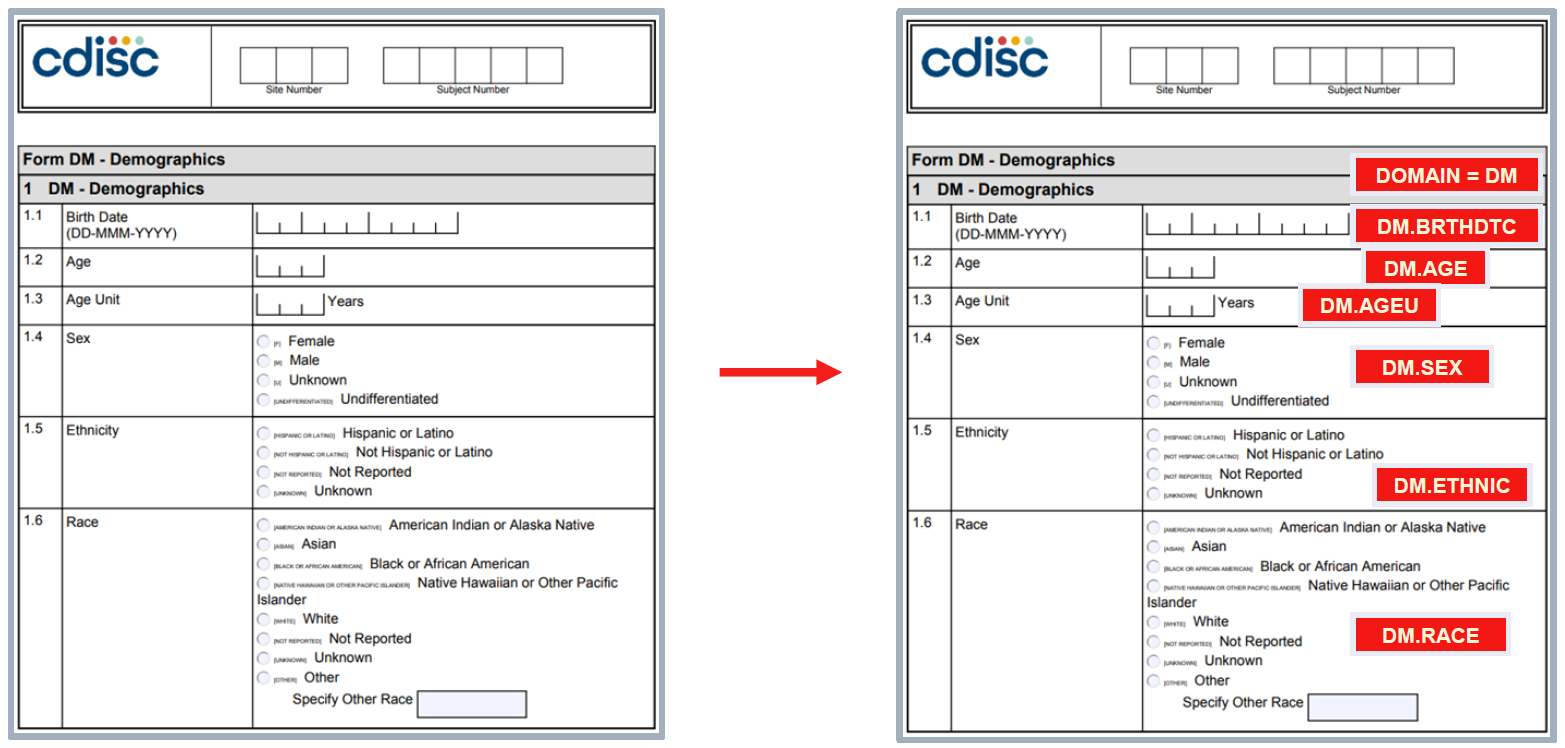
CRF-to-SDTM traceability example
3. SDTM: Study Data Tabulation Model
SDTM is the standard for organizing and formatting clinical trial tabulation data. It provides a consistent structure for domains such as:
- DM – Demographics
- AE – Adverse Events
- CM – Concomitant Medications
- EX – Exposure
- LB – Laboratory Tests
- VS – Vital Signs
- MH – Medical History
- DS – Disposition
- SUPP– – Supplemental Qualifiers
- Trial Design domains such as TA, TE, TV, TI, TS
CDISC states that SDTM streamlines data collection, management, analysis, reporting, aggregation, sharing, reuse, due diligence, and regulatory review. SDTM is also one of the required standards for FDA and PMDA submissions. (CDISC – SDTM)
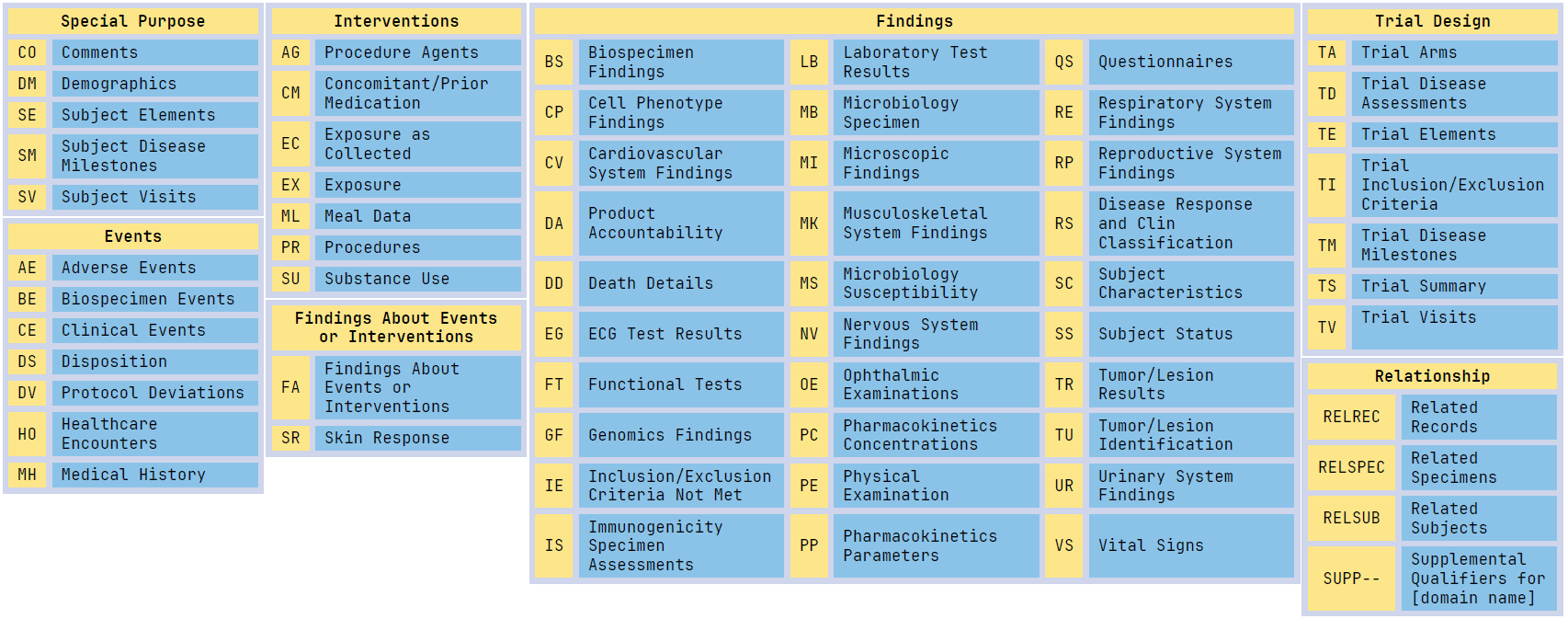
SDTM datasets classification
The key purpose of SDTM is not statistical analysis. Its purpose is to represent collected clinical data in a standard tabulation format that regulators and reviewers can navigate efficiently.
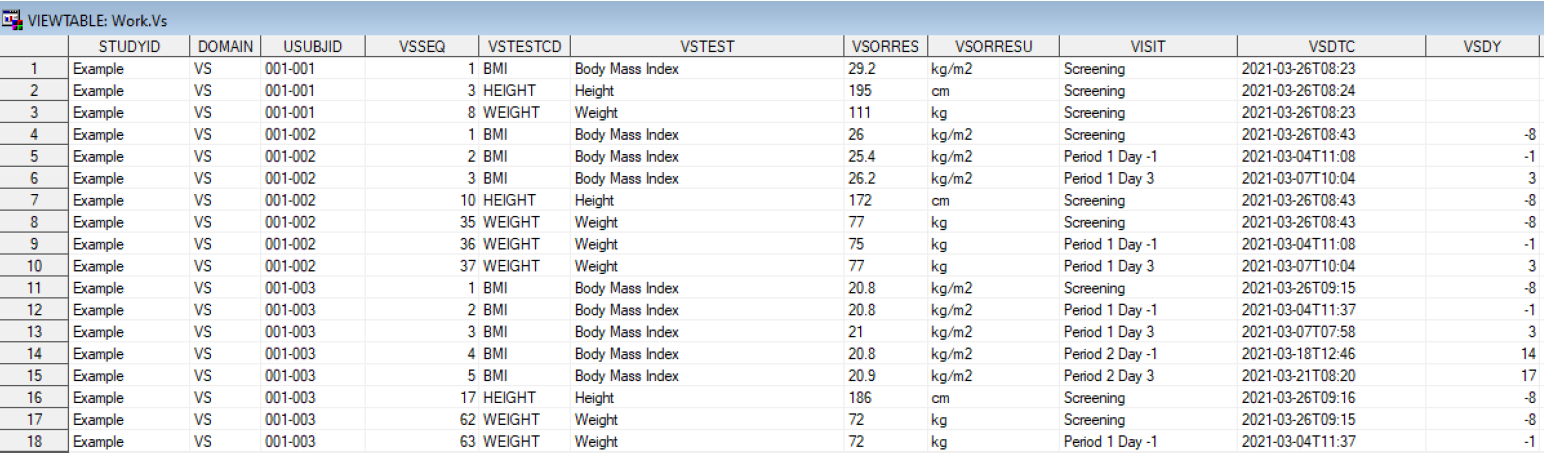
SDTM dataset example
For SAS programmers, SDTM is often the first major transformation layer:
Raw / EDC / vendor data → SDTM domains → Define-XML → reviewer-ready tabulation package
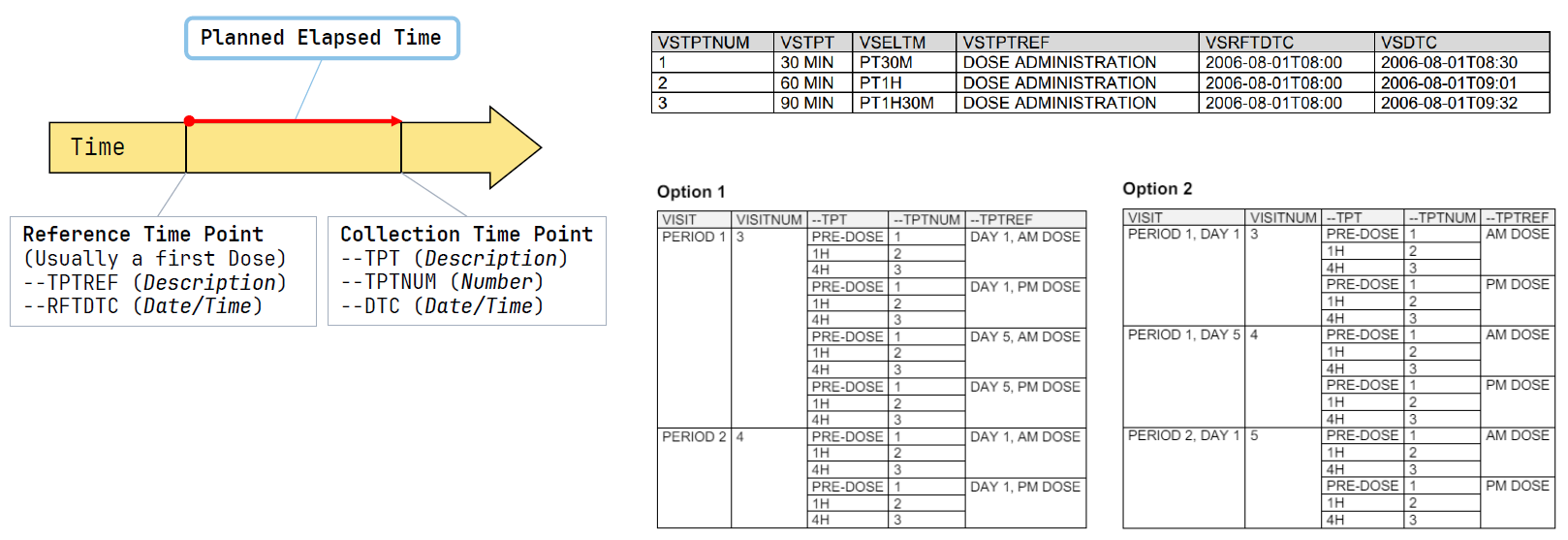
How to collect time in SDTM
Good SDTM implementation should be clean, traceable, controlled terminology-compliant, and aligned with the protocol and annotated CRF.
4. ADaM: Analysis Data Model
ADaM is the CDISC standard for analysis-ready datasets.
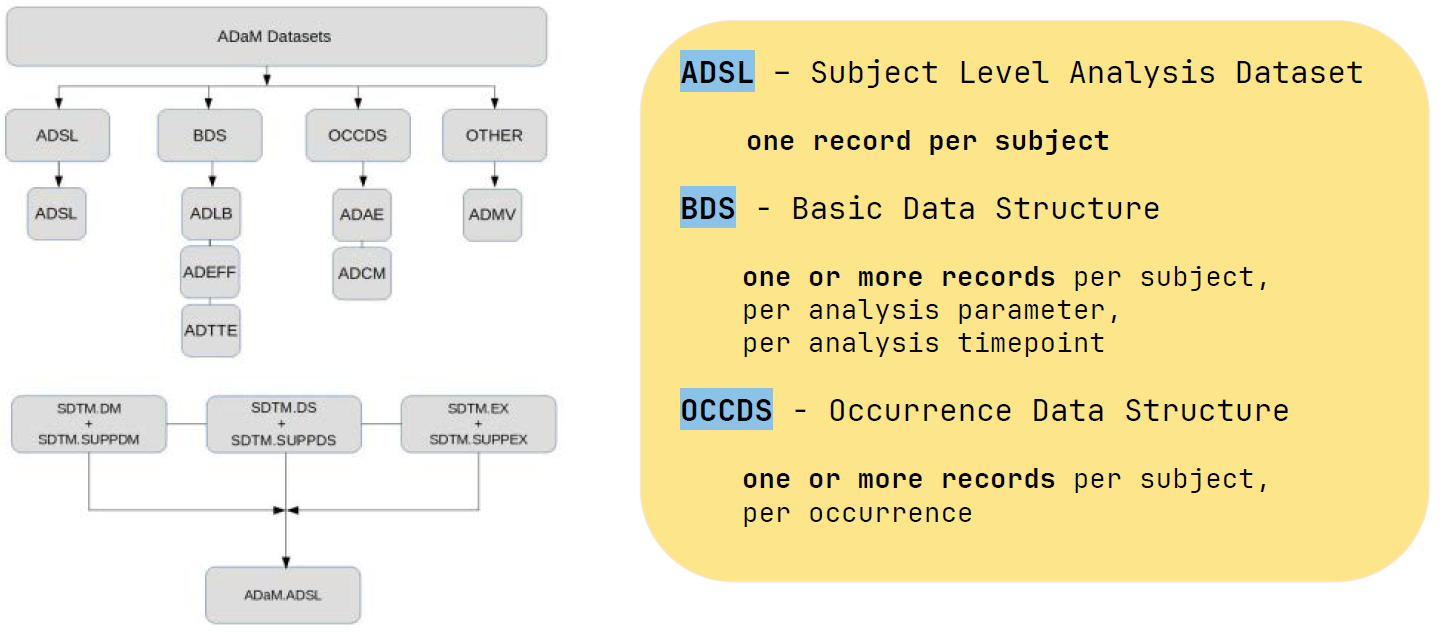
While SDTM represents collected data, ADaM represents data prepared for statistical analysis. ADaM supports the generation, replication, and review of statistical analyses, and provides traceability between analysis results, analysis datasets, and SDTM data. (CDISC – ADaM)
Typical ADaM datasets include:
- ADSL — Subject-Level Analysis Dataset
- ADAE — Adverse Event Analysis Dataset
- ADLB — Laboratory Analysis Dataset
- ADTTE — Time-to-Event Analysis Dataset
- ADEFF / ADQS / custom BDS datasets depending on endpoints and analysis needs
The most important concept in ADaM is traceability.
A reviewer should be able to understand how a value in a table was produced, which ADaM variable was used, how it was derived, and where the source information came from in SDTM.
In simple terms: SDTM tells the story of what was collected. ADaM tells the story of what was analysed.
5. SEND: Standard for Exchange of Nonclinical Data
SEND is the implementation of SDTM for nonclinical studies. It standardizes how animal toxicology and other nonclinical study data are collected and presented for regulatory submission.
CDISC describes SEND as a way to collect and present nonclinical data in a consistent format, and FDA lists SEND among currently supported study data standards for nonclinical data.
This matters because nonclinical safety packages are an important part of drug development. SEND helps reviewers navigate toxicology data more consistently before and alongside human clinical development.
6. QRS: Questionnaires, Ratings, and Scales
QRS-related CDISC supplements and terminology support the representation of questionnaires, ratings, and scales used in clinical research. These may include patient-reported outcomes, clinician-reported outcomes, performance outcomes, and other assessment instruments.
CDISC develops SDTMIG and ADaMIG QRS supplements, including controlled terminology and examples for structuring instrument data in a standard format. (CDISC – QRS)
This is especially important in therapeutic areas where endpoints depend on scoring instruments, such as dermatology, neurology, psychiatry, pain, oncology symptoms, and quality-of-life assessments.
A QRS implementation should not only map questions and responses. It should also preserve scoring logic, timing, versioning, and analysis traceability.
7. Controlled Terminology
Controlled Terminology is one of the most important and most underestimated – parts of CDISC implementation.
CDISC Controlled Terminology provides standard codelists and submission values used across CDISC-defined datasets. It tells teams how to submit a collected concept in a standardized way. CDISC terminology is developed with the National Cancer Institute Enterprise Vocabulary Services and supports Foundational and Therapeutic Area Standards. (CDISC – CT)
For example, controlled terminology helps standardize values for:
- sex
- race
- ethnicity
- adverse event severity
- laboratory test codes
- units
- route of administration
- visit types
- disposition events
- parameter codes
- QRS test codes
A technically valid dataset can still fail review expectations if terminology is inconsistent, outdated, or incorrectly applied.
For submission work, CT version control is essential. Teams should document which terminology package was used and ensure consistency between datasets, define.xml, reviewer guides, and validation outputs.
8. Therapeutic Area Standards
Therapeutic Area Standards extend CDISC Foundational Standards for disease-specific needs. They provide metadata, examples, and guidance for implementing CDISC in specific therapeutic areas such as oncology, cardiovascular disease, neurology, dermatology, infectious disease, and others.
They are useful because not all clinical concepts fit cleanly into general domains without therapeutic context.
For example, oncology studies may require specific handling of tumor response, lesions, RECIST-related assessments, prior therapies, and disease progression endpoints.
Therapeutic Area guidance helps reduce study-by-study inconsistency and supports better cross-study comparability.
CDISC Data Exchange Standards
Content standards define what the data should look like.
Data exchange standards define how data and metadata move between systems.
This is critical because clinical trials rarely use one system. A single study may involve EDC, ePRO, RTSM/IWRS, central labs, imaging vendors, safety databases, statistical programming environments, metadata repositories, clinical data warehouses, and regulatory submission platforms.
CDISC Data Exchange Standards facilitate the sharing of structured data across different information systems. (CDISC – DES)
1. ODM: Operational Data Model
ODM is a vendor-neutral and platform-independent format for exchanging and archiving clinical research data and metadata. It can include clinical data, metadata, administrative data, reference data, and audit information. CDISC describes ODM as widely used for representing CRF content in electronic data capture tools.
In practice, ODM is often relevant for:
- EDC metadata exchange
- CRF design transfer
- audit trail representation
- clinical data export
- archival
- integration between systems
ODM supports the idea that clinical data should not be trapped in one vendor’s system.
2. Define-XML
Define-XML is one of the most important submission metadata standards.
It describes the structure of submitted datasets: datasets, variables, controlled terminology, origins, derivations, value-level metadata, comments, computational methods, and links to supporting documents.
CDISC states that Define-XML transmits metadata describing tabular dataset structures and is required by FDA and PMDA for every study in each electronic submission. (CDISC – DEFINE.XML)
For reviewers, define.xml is the map to the submission datasets.
For programmers, define.xml is not an afterthought. It should be developed in parallel with SDTM and ADaM, not assembled at the very end.
A good define.xml should make the dataset package understandable without requiring the reviewer to reverse-engineer the programming logic.
3. Dataset-JSON and Dataset-XML
Historically, regulatory submissions have relied heavily on SAS XPT transport files. However, XPT has well-known technical limitations, including short variable names, short labels, and character length constraints.
Dataset-XML was developed as a non-proprietary alternative that works with Define-XML metadata. Dataset-JSON is the more modern JSON-based exchange standard designed for tabular data exchange, regulatory submission scenarios, and API-based data exchange. (CDISC – JSON)
FDA has also noted that CDER and CBER have conducted preliminary testing of Dataset-JSON as a potential replacement for XPT v5, with further evaluation planned. (U.S. Food and Drug Administration)
The direction is evolving toward more flexible, machine-readable, API-friendly formats.
4. Analysis Results Standard
The Analysis Results Standard, previously often discussed in relation to Analysis Results Metadata, provides a structured way to describe and organize analysis results.
CDISC developed the Analysis Results Standard to support automation, reproducibility, reusability, and traceability of analysis results. It aims to provide traceability to the protocol or SAP and to input ADaM data. (CDISC – ARS)
This is highly relevant for the future of automated reporting.
Instead of treating tables, listings, and figures as isolated outputs, analysis results metadata helps describe:
- what analysis was performed
- which population was used
- which endpoint or parameter was analyzed
- which method was applied
- which ADaM dataset and variables supported the result
- how the result links back to the SAP
For statistical programmers, this is where automation and traceability meet.
5. LAB: Laboratory Data Model
The LAB standard supports the acquisition and exchange of laboratory data, primarily between laboratories and sponsors or CROs. CDISC describes LAB as specifically designed for interchange of lab data acquired in clinical trials. (CDISC – LAB)
Laboratory data is one of the most common and operationally complex data flows in clinical research. Standardization improves consistency in test names, units, reference ranges, specimen information, and transfer structures.
CDISC Library
The CDISC Library is the authoritative source for CDISC standards metadata. It provides access to versioned standards, controlled terminology, metadata relationships, and machine-readable formats via a browser and REST API. (CDISC – library)
This matters because CDISC is no longer only a set of PDF implementation guides.
Modern standards implementation increasingly depends on metadata-driven processes:
- automated CRF design
- metadata repositories
- SDTM and ADaM specification generation
- validation rule management
- controlled terminology version control
- define.xml automation
- standards impact analysis
- version comparison and migration
For organizations serious about automation, CDISC Library should become part of the standards governance infrastructure.
Why CDISC Adoption Matters
CDISC adoption creates value far beyond “being compliant.”
1. Regulatory Readiness
FDA currently supports CDISC SEND, SDTM, ADaM, and Define-XML for study data submissions to CDER and CBER, and study data must be in a format supported by FDA at the time of the study start date according to the FDA Data Standards Catalog. (U.S. Food and Drug Administration)
A submission package that follows CDISC standards is easier for reviewers to load, navigate, validate, and interpret.
2. Traceability
CDISC supports traceability from protocol to CRF, from CRF to SDTM, from SDTM to ADaM, and from ADaM to statistical outputs.
This is one of the most important concepts in clinical programming.
Traceability is what allows a reviewer, auditor, or internal quality team to understand how a final result was created.
3. Data Quality
Standard structures reduce ambiguity. Controlled terminology reduces inconsistent coding. Metadata improves transparency. Validation rules help detect issues before submission.
CDISC does not guarantee quality by itself, but it creates the framework in which quality can be assessed more consistently.
4. Efficiency and Reuse
Standardized datasets are easier to reuse across studies, integrated summaries, pooled analyses, data warehouses, and future development programs.
The benefit becomes especially visible when multiple studies use consistent SDTM, ADaM, controlled terminology, parameter conventions, and metadata standards.
5. Cross-Functional Alignment
CDISC forces teams to align early.
A good CDISC implementation requires agreement between clinical, data management, statistics, programming, medical writing, regulatory, and vendors.
That alignment reduces late-stage surprises.
Implementing CDISC Standards: A Practical Roadmap
Step 1: Start with the Protocol
CDISC implementation should not start when the database is locked.
It should start when the protocol is being designed.
Key questions include:
- What are the primary and secondary endpoints?
- Which assessments are critical to quality?
- Which data will support estimands and analysis populations?
- Which visits and timepoints matter for analysis?
- Which data will be collected directly, derived, or transferred from vendors?
- Which controlled terminology and standards versions will be used?
A protocol that is not data-aware creates downstream problems.
Step 2: Design CDASH-Aligned CRFs
CRF design should support downstream SDTM mapping.
This means thinking early about:
- variable intent
- collection wording
- controlled terminology
- visit structure
- date/time precision
- units
- repeat forms
- supplemental qualifiers
- vendor data transfer requirements
A CRF should not only be easy for a site to complete. It should also support clean tabulation and analysis.
Step 3: Build SDTM with Clear Traceability
SDTM mapping should be documented in specifications.
For each domain, the team should define:
- source datasets
- source variables
- mapping logic
- controlled terminology
- derivations
- supplemental qualifiers
- relationship records
- assumptions
- known issues
- validation findings and resolutions
The goal is not only to produce datasets. The goal is to produce datasets that can be reviewed.
Step 4: Build ADaM Around the SAP
ADaM should be driven by the Statistical Analysis Plan.
Each analysis dataset should support a defined analysis purpose. Each derived variable should have clear logic. Each analysis flag should be justified. Each parameter should be traceable.
A strong ADaM package usually includes:
- ADSL as the foundation
- clear population flags
- treatment variables
- analysis dates and relative days
- baseline definitions
- change-from-baseline logic
- endpoint derivations
- censoring rules
- parameter-level metadata
- traceability to SDTM
- traceability to TFLs
ADaM is where statistical thinking and programming implementation must meet.
Step 5: Validate Early and Repeatedly
Validation should not be a final step.
Use validation throughout development:
- SDTM validation during mapping
- ADaM validation during dataset development
- controlled terminology checks
- define.xml validation
- cross-dataset consistency checks
- reviewer guide consistency checks
- traceability checks
- independent QC programming
- log checks
- metadata checks
Tools are important, but expert review is still essential.
A dataset can pass automated validation and still be conceptually wrong.
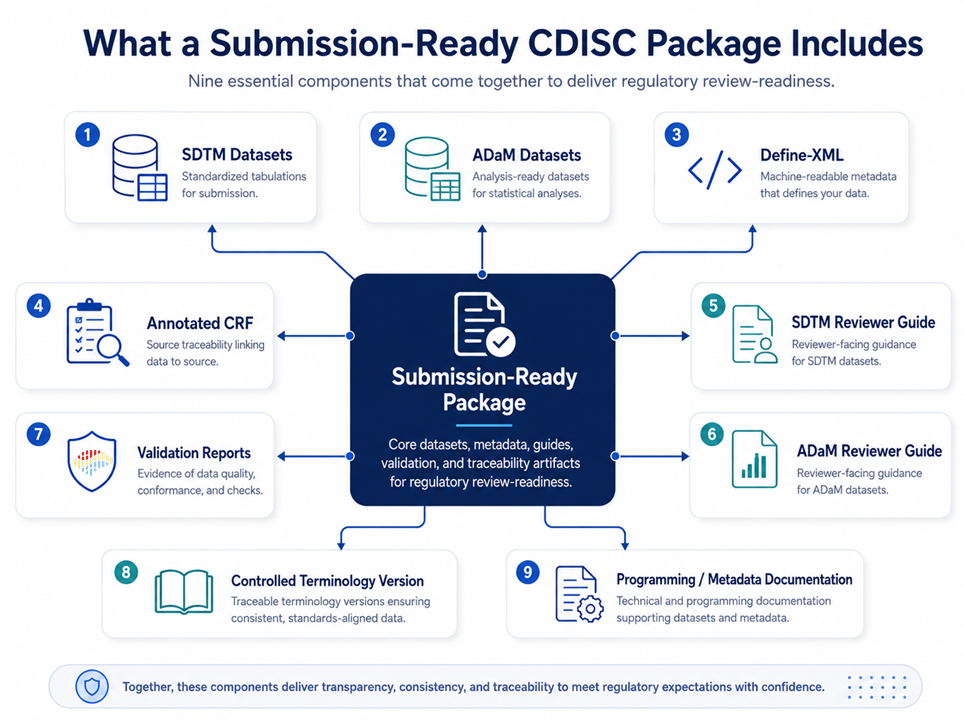
Step 6: Prepare Submission Metadata and Reviewer Guides
A regulatory submission is more than datasets.
A strong package includes:
- SDTM datasets
- ADaM datasets
- define.xml
- annotated CRF
- SDTM reviewer guide
- ADaM reviewer guide
- programs, where required or expected
- validation reports
- controlled terminology version documentation
- clear explanations of important deviations or non-standard decisions
Reviewer guides are not administrative documents. They are part of the communication between sponsor and reviewer.
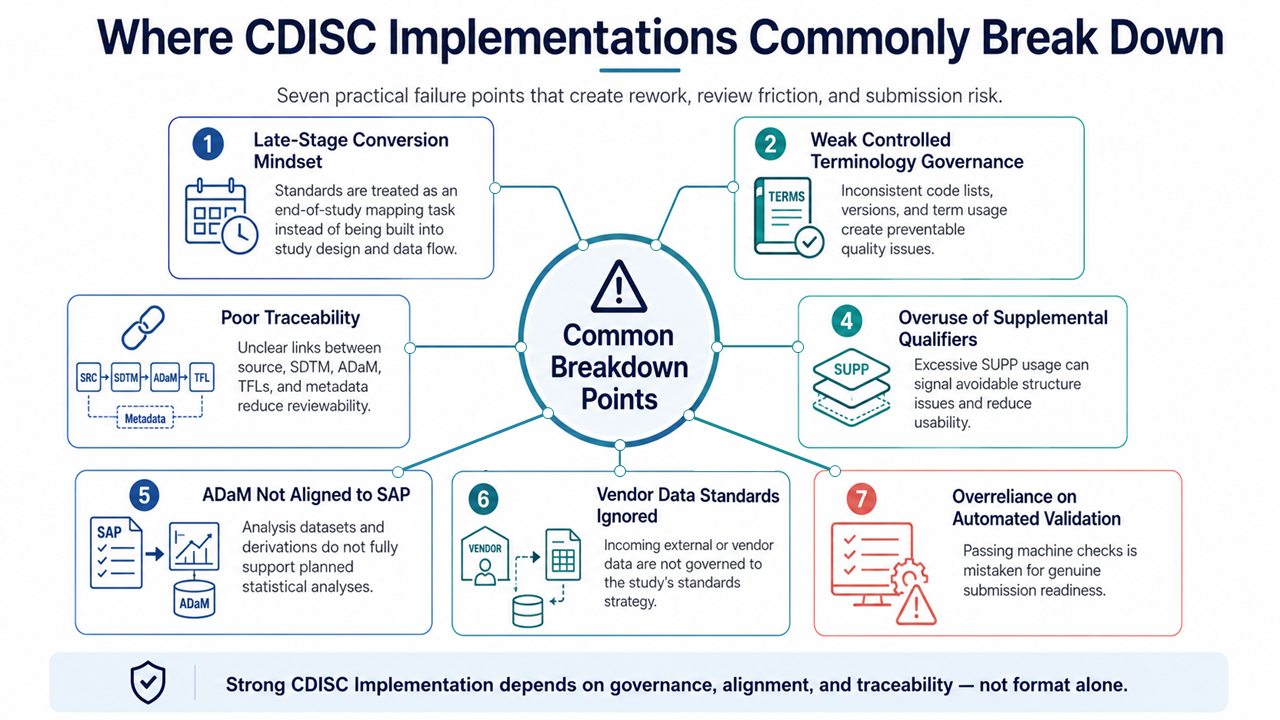
Common CDISC Implementation Pitfalls
Treating CDISC as a Late-Stage Conversion
This is one of the most common mistakes.
If CDISC is treated as a final formatting exercise, the team often discovers too late that the protocol, CRF, vendor data, SDTM, ADaM, and SAP are not aligned.
Weak Controlled Terminology Governance
Outdated terminology, sponsor-specific values, inconsistent units, and unclear parameter codes can create avoidable validation issues.
Poor Traceability
If the path from result to ADaM to SDTM to source is unclear, the package becomes difficult to review and defend.
Overusing Supplemental Qualifiers
SUPP– domains are useful, but excessive use may indicate poor domain modelling or missed standard variables.
Building ADaM Without the SAP
ADaM should not be a generic transformation of SDTM. It should be built to support planned analyses.
Ignoring Vendor Data Standards
Central labs, ECG, imaging, ePRO, wearables, and specialty vendors should be integrated into the standards strategy early.
Relying Only on Automated Validation
Automated tools detect many structural issues, but they do not replace clinical, statistical, and regulatory judgement.
The Future of CDISC
CDISC is evolving from document-based standards toward machine-readable, metadata-driven standards.
Several trends are especially important.
Digital Protocols and DDF / USDM
Structured protocols will increasingly support downstream automation: CRF generation, schedule of activities, SDTM Trial Design domains, registry content, and analysis planning.
Dataset-JSON and Modern Data Exchange
Dataset-JSON reflects the shift toward more flexible and API-friendly data exchange. This is important as the industry moves beyond historical file format limitations.
Metadata-Driven Automation
The future of CDISC implementation will depend heavily on metadata repositories, reusable standards, controlled terminology automation, define.xml generation, and standards APIs.
AI and Standards
AI can help with mapping, metadata comparison, protocol digitization, validation support, and code generation.
But AI without standards can accelerate inconsistency.
The real value comes when AI is combined with structured, governed, version-controlled standards.
Real-World Data and Decentralized Trials
As clinical research incorporates more external data sources, remote assessments, digital health technologies, and real-world data, standards become even more important.
The more diverse the data sources, the more important it becomes to define structure, provenance, metadata, traceability, and fitness for purpose.
How to Learn CDISC Practically
One practical way to learn CDISC is to start from real studies.
ClinicalTrials.gov provides structured study records and includes document fields for uploaded protocols and statistical analysis plans when available. Its data structure includes indicators for whether uploaded documents include a protocol or SAP.
A useful learning exercise is:
- Find a real completed study on ClinicalTrials.gov.
- Read the protocol and SAP if available.
- Identify endpoints, visits, assessments, populations, and key safety data.
- Sketch the expected CDASH forms.
- Map the expected SDTM domains.
- Design the ADaM datasets needed for the SAP.
- Draft key TFL shells.
- Think through define.xml metadata and traceability.
This is how CDISC becomes practical rather than theoretical.
Conclusion
CDISC standards are not just technical specifications. They are the backbone of modern clinical research data flow.
They help teams collect data consistently, structure it for review, prepare it for analysis, document it transparently, exchange it between systems, and submit it to regulators in a predictable format.
The strongest CDISC implementations start early, connect protocol design with data collection and analysis, maintain clear traceability, and treat metadata as a strategic asset.
For sponsors, CROs, programmers, data managers, statisticians, and regulatory teams, CDISC competence is no longer optional.
It is one of the core capabilities required to deliver reliable, reviewable, submission-ready clinical evidence.
CDISC works best when it is implemented as an end-to-end strategy, not as a last-minute conversion step.
If your team is building SDTM, ADaM, Define-XML, reviewer guides, or metadata-driven programming workflows, the key question is not only “Are we compliant?”
The better question is:
Can a reviewer clearly understand and reproduce the path from protocol question to submitted result?